1. 데이터 수집하기
데이터 수집 : 분석할 데이터를 준비하는 과정을 이르는 말.
데이터를 준비하는 방법 ?
- 직접 데이터를 입력하기 - 벡터나 데이터 프레임 등을 R에 함수로 입력하기
- 외부 데이터를 가져오기 - .txt, .csv, .xlsx 등과 같이 이미 만들어져 있는 데이터 파일을 가져오기
- 서버에서 데이터를 호출하기
- 이때 직접 입력하거나 외부에서 가져온 데이터, 즉 가공하지 않은 처음의 데이터는 원시데이터 (raw data) 라고 한다.
1) 직접 데이터 입력하기
원시 데이터 입력 : R에서 분석할 데이터 (값) 을 직접 입력하여 저장하는 단계
c() 함수를 사용하여 값을 변수에 할당함 (벡터 만드는 법과 동일)
변수명 <- c(값)
x <- c(1:7)
예제)
ID에는 1부터 5까지, SEX에는 F, M, F, M, F를 할당하여 직접 데이터를 입력하고 이 데이터를 데이터프레임으로 만들어 View() 함수로 데이터 조회하기
ID3 <- c(1:5)
SEX2 <- c("F", "M", "F", "M", "F")
DATA <- data.frame(ID3, SEX2)
View(DATA)
- 데이터 조회하는 2가지 방법
1) console 탭에서 확인하는 방법
2) View() 함수로 데이터 뷰어로 확인하는 방법
- 데이터 뷰어를 이용하면 데이터를 엑셀처럼 정리된 상태로 볼 수 있고 간단한 필터를 적용하거나 정렬을 실행할 수 있어 편리하다. 이는 주로 시스템으로 처리한 데이터가 어떤 형태로 표현되었는지 확인할 때 사용하며, 가공되지 않은 원시데이터만 확인할 수 있다.
2) 외부 데이터 가져오기 : TXT 파일
TXT 파일은 read.table() 함수를 이용하여 데이터 프레임으로 가져올 수 있다.
read.table("원시 데이터", header = FALSE, skip = 0, nrows = -1, sep = "", ...)
원시데이터를 원하는 데이터 프레임 형태로 가져올 때 사용하는 read.table() 함수의 옵션 4가지
- header : 원시데이터의 1행이 변수명인지 아닌지 판단한다.
| a logical value indicating whether the file contains the names of the variables as its first line. If missing, the value is determined from the file format: header is set to TRUE if and only if the first row contains one fewer field than the number of columns. |
- skip : 특정 행까지 제외하고 데이터를 가져온다.
| integer: the number of lines of the data file to skip before beginning to read data. |
- nrows : 특정 행까지 데이터를 가져온다.
| integer: the maximum number of rows to read in. Negative and other invalid values are ignored. |
- sep : 데이터의 구분 문자를 지정한다.
| the field separator character. Values on each line of the file are separated by this character. If sep = "" (the default for read.table) the separator is ‘white space’, that is one or more spaces, tabs, newlines or carriage returns. |
* 옵션들은 사용하지 않으면 구문에서 생략할 수 있다. 생략하면 옵션 기본값으로 원시데이터를 가져온다.
ex_data <- read.table("C:/Rstudy/sources/data_ex.txt", encoding="EUC-KR", fileEncoding = "UTF-8")
View(ex_data)* 경로를 쓸 때는 역슬래쉬\가 아닌 슬래쉬/를 사용한다.
* encoding, fileEncoding 옵션 : 한글이 포함된 데이터에서 한글 제대로 표시 안되는 오류 막을 수 있게 사용
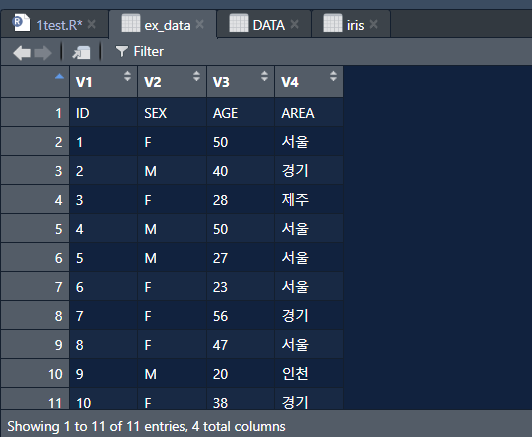
- 변수를 설명하는 ID, SEX, AGE, AREA가 변수명이 아니라 값이 되고 테이블 첫번째 행에는 임의의 변수명이 삽입됨.
이럴 때는 read.table() 함수의 header 옵션을 사용하여 원시 데이터에 변수명이 있음을 지정해주어야함.
(1) header 옵션 : 원시데이터 1행이 변수명인지 아닌지 판단하는 옵션
header = TRUE : 원시데이터의 1행이 변수명으로 지정됨 (테이블 1행이 됨)
header = FALSE : 원시데이터의 1행이 값이 됨 (테이블 2행이 되고, 1행에는 임의의 변수명이 삽입됨)
ex_data1 <- read.table("C:/Rstudy/sources/data_ex.txt",
encoding="EUC-KR", fileEncoding = "UTF-8", header = TRUE)
View(ex_data1)
- 만약 원시데이터에 ID, SEX, AGE, AREA 같이 변수명으로 사용할 행이 없다면, col.names 옵션을 사용한다.
col.names 옵션은 원시 데이터에 변수명이 없더라도 데이터 프레임에 변수명을 부여할 수 있다.
# 변수명으로 사용할 값을 벡터 형태로 var_name에 할당
var_name <- c("ID", "SEX", "AGE", "AREA")
ex_data1 <- read.table("C:/Rstudy/sources/data_ex_col.txt",
encoding="EUC-KR", fileEncoding = "UTF-8", header = FALSE, col.names = var_name)
View(ex_data1)- 이처럼 행 이름을 부여하고 싶을 땐 row.names 옵션을 사용할 수 있음
(2) skip 옵션 : 데이터 전체가 아니라 옵션에 지정한 특정 행까지 제외하고 그 이후 행부터 가져옴

위 데이터셋에서 ID 5번 행부터 불러오고 싶다.
#skip 옵션 사용
ex_data2 <- read.table("C:/Rstudy/sources/data_ex.txt", encoding="EUC-KR", fileEncoding = "UTF-8",
header = TRUE, skip = 4)
View(ex_data2)
ex_data3 <- read.table("C:/Rstudy/sources/data_ex.txt", encoding="EUC-KR", fileEncoding = "UTF-8",
header = FALSE, skip = 5)
View(ex_data3)
ex_data4 <- read.table("C:/Rstudy/sources/data_ex.txt", encoding="EUC-KR", fileEncoding = "UTF-8",
header = FALSE, skip = 5, col.names=var_name)
View(ex_data4)


(3) nrows 옵션 : 몇개의 행을 불러올지 지정
변수명과 ID 1부터 4까지만을 불러오고 싶다.
#nrows 옵션 사용
ex_data5 <- read.table("C:/Rstudy/sources/data_ex.txt", encoding="EUC-KR", fileEncoding = "UTF-8",
header = TRUE, nrows = 4)
View(ex_data5)
(4) sep 옵션 : 데이터 구분자를 지정하는 옵션
앞선 실습에서는 값 구분이 TAB으로 되어있었기 때문에 옵션 설정 없이 가져올 수 있었다.
만약 쉼표(,) 로 구분되어 있다면 어떻게 하면 될까?

#sep 옵션
ex_data6 <- read.table("C:/Rstudy/sources/data_ex1.txt", encoding="EUC-KR", fileEncoding = "UTF-8",
header = TRUE, sep = ",")
View(ex_data6)3) 외부 데이터 가져오기 : CSV 파일
CSV 파일은 .csv 확장자를 가진 파일로 쉼표(,)를 이용해 열을 구분하는 데이터이다. 값은 큰따옴표에 싸여있다.
read.csv() 함수를 사용한다. 사용법은 read.table() 함수와 비슷.
read.csv("원시데이터")
#CSV 파일 불러오기
ex_data7 <- read.csv("C:/Rstudy/sources/data_ex.csv")
View(ex_data7)
- read.csv() 함수는 따로 옵션을 설정하지 않아도 원시 데이터의 1행을 변수명으로 가져온다. 만약 값이 비어있다면 임의로 지정된다.
4) 외부 데이터 가져오기 : 엑셀 파일
read.excel("원시데이터")#excel 파일 불러오기
install.packages("readxl")
library(readxl)
ex_data8 <- read_excel("C:/Rstudy/sources/data_ex.xlsx")
View(ex_data8)
- read_excel() 함수는 기본적으로 첫번째 시트 탭의 데이터를 가져오는데, 다른 탭 시트 데이터를 가져오려면 sheet 옵션을 사용한다.
ex_data82 <- read_excel("C:/Rstudy/sources/data_ex.xlsx", sheet = 2)5) 외부 데이터 가져오기 : XML 파일
XML : eXtensible Markup Language
HTML 과 비슷하지만 데이터를 보여주는 것이 아닌 저장하고 전달하는 목적으로 만들어진 형식.
HTML 처럼 태그가 미리 정의되어 있지 않고 태그를 사용자가 직접 정의한다.
HTML 처럼 <> 괄호로 이루어져있다.
xmlToDataFrame() 함수를 사용한다. (XML 패키지에 있음)
xmlToDataFrame("원시데이터")6) 외부 데이터 가져오기 : JSON 파일
JSON : JavaScript Object Notation
: 데이터를 전달하는 목적으로 만들어진 형식.
서버-클라이언트 통신 간 데이터를 받아 객체나 변수에 할당해서 사용할 때 많이 사용
XML 파일보다 구문이 짧고 속도가 빨라 실무에서 흔히 사용
데이터 안에 다시 데이터가 정의된 중첩데이터 (nested data) 구조로 이루어져 있음.
fromJSON() 함수를 사용 ( jsonlite 패키지에 있음 )
fromJSON("원시 데이터")* fromJSON 함수는 데이터 프레임으로 가져오는 함수가 아니기 때문에 View() 함수가 아니라 str() 함수로 데이터 구조를 살펴볼 수 있음.
| 함수 | 기능 |
| read.table() | TXT 파일을 가져온다 |
| read.csv() | CSV 파일을 가져온다 |
| read_excel() | (readxl 패키지) 엑셀 파일을 가져온다 |
| xmlToDataFrame() | (XML 패키지) XML 파일을 가져온다 |
| fromJSON() | (jsonlite 패키지) JSON 파일을 가져온다 |
'기타 > R' 카테고리의 다른 글
| R 독학하기 - 4 (2) (1) | 2024.02.14 |
|---|---|
| R (R studio) 업데이트하는 방법 / 패키지 업데이트하는 방법 (1) | 2024.02.13 |
| R 독학하기 - 3 (1) | 2024.02.13 |
| R 독학하기 - 2 (1) | 2024.02.08 |
| R 독학하기 - 1 (1) | 2024.02.05 |



