[1] dplyr 패키지
- dplyr 패키지 : 데이터 처리 패키지로, 사용자 친화적으로 데이터 프레임을 조작할 수 있다.
- R의 기본 내장 함수만으로도 데이터를 가공할 수 있지만, dplyr 패키지를 사용하면 프로그래밍에 익숙하지 않아도 함수를 쉽고 빠르게 사용할 수 있다는 장점이 있다.
1. dplyr 패키지 설치 및 로드
install.packages("dplyr")
library(dplyr)
- dplyr을 로드했을 때 위와 같은 메시지가 출력된다는 것은 오류는 아니고 해당 패키지에 기존에 사용중인 함수와 동일한 이름의 함수가 있다는 알림 메시지이다.
- 이처럼 다른 패키지에 동일한 함수가 있을 때는 특정패키지임을 표시하는 :: 더블 콜론 연산자를 사용한다.
- 예를 들어 dplyr 패키지의 filter() 함수를 사용한다면 dplyr::filter() 형태로 작성한다.
- 위와같은 메시지 일시적으로 안보이게 하는 방법 : warn.confilct = FALSE 옵션 (ex. library(dplyr, warn.confilct = FALSE)
- 실습에 사용할 데이터 세트인 mtcars(R 내장 데이터세트) 구조 파악하기 -> nrow() 함수 = 행 개수 확인, str() 함수 = 데이터 구조 확인
nrow(mtcars)
str(mtcars)
- 32행, 11열 로 구성된 데이터 프레임임. 각 11개 열에는 숫자형 자료 들어있음.
- mpg(연비), 실린더 개수(cyl) 등 연료 소비와 관련된 변수 11개와 자동차 모델 32종 정보
2. 데이터 추출 및 정렬하기
- dplyr 패키지에 포함된 함수로 데이터 세트에서 필요한 데이터만 추출하거나 지정한 기준에 따라 데이터를 내림차순/오름차순으로 정렬할 수 있다.
1) 행 추출하기 : filter() 함수
filter() 함수 : 조건에 맞는 데이터 행을 필터링하는 함수
filter(데이터, 조건문)ex) filter() 함수로 실린더 개수가 4기통인 자동차만 추출하기
filter(mtcars, cyl == 4)
- 조건은 & 연산자를 사용해 여러개 지정할 수 있음.
ex) 6기통 이상의 자동차 중에서 연비가 20miles/gallon을 초과하는 자동차만 추출하기
filter(mtcars, cyl >= 6 & mpg > 20)
2) 열 추출하기 : select() 함수
select() 함수 : 지정한 변수 열만 추출할 떄 사용
select(데이터, 변수명1, 변수명2, ...)ex) select() 함수로 mtcars 데이터 세트에서 변속기 am (구분) 과 gear (기어) 데이터만 추출하기
select(mtcars, am, gear)
- 데이터 양이 많으므로 head() 함수를 써서 앞부분만 확인해본다.

- 만약 unused arguments () 오류 메시지가 나타난다면, 이는 다른 패키지에 포함된 select() 함수가 사용되었다는 뜻이니 :: 연산자를 사용해서 dplyr 패키지의 select() 함수를 사용해준다.
dplyr::select(mtcars, am, gear)3) 정렬하기 : arrange() 함수
arrange() 함수 : 데이터를 오름차순으로 정렬할 때 사용
- 여러 개의 열을 기준으로 지정할 수 있다.
- desc() 함수를 같이 사용하면 내림차순으로 정렬 가능
arrange(데이터, 변수명1, 변수명2, ...)
arrange(데이터, 변수명1, 변수명2, ..., desc(변수명))오름차순 정렬 기준
- 숫자형 변수 : MISSING ( = NA = 결측치(비어있는 값)를 의미), 음수, 0, 양수
- 문자형 변수 : 빈칸, !"#$%&'()*+-./0123456789:;<=>?@A~Z[/]_
ex) mtcars 데이터 세트에서 무게(wt)를 기준으로 오름차순 정렬한 후 head() 함수로 앞부분만 출력하기
head(arrange(mtcars, wt)
- head() 함수를 사용하면 상위 6개 데이터만 출력됨 (기본값)
- 오름차순과 내림차순을 혼용해서 사용할 수 있음
ex) 연비(mpg)를 기준으로 오름차순 정렬한 후 무게(wt)를 기준으로 내림차순 정렬하기
head(arrange(mtcars, mpg, desc(wt)))
- 이처럼 정렬 기준이 여러개일때는 데이터를 첫번쨰 기준으로 정렬한 후 이중에 첫번째 값이 같은 행은 두번째 기준으로 다시 정렬한다.
3. 데이터 추가 및 중복 데이터 제거하기
- 기본 데이터 세트에 새로운 열을 추가하거나 중복되는 데이터를 제거할 때 dplyr 패키지의 함수를 활용할 수 있음
1) 열 추가하기 : mutate() 함수
mutate() 함수 : 데이터 세트에 열(column)을 추가할 떄 사용
- 기존 열을 가공한 후 그 결괏값을 기존 열이나 새로운 열에 할당
mutate(데이터, 추가할 변수 이름 = 조건1, ...)ex) mtcars 데이터 세트에 years라는 생산일자 열 새로 추가하기 - 값에는 일괄적을 1974를 추가하여 1974년 데이터임을 표시
head(mutate(mtcars, years = "1974"))
- carb 변수 뒤에 years 변수와 값이 일괄 추가되어 열이 생성된다.
ex) 자동차별 연비(mpg) 순위를 rank() 함수로 구하여 mpg_rank 열 추가하여 할당하기
head(mutate(mtcars, mpg_rank = rank(mpg)))

- rank() 함수는 데이터 순위를 확인할 때 사용한다. 값이 같을 때는 소숫점 순위로 반환한다.
2) 중복 값 제거하기 : distinct() 함수
distinct() 함수 : 중복 값을 제거할 때 사용
distinct(데이터, 변수명)ex) mtcars 데이터 세트에서 실린더 개수(cyl)에 따른 종류와 기어 개수(gear)에 따른 종류를 확인하기
distinct(mtcars, cyl)
distinct(mtcars, gear)
- 중복값을 제거해보니 cyl, gear 열의 값이 각각 3종류인걸 확인할 수 있다.
- 이렇게 중복 값을 제거하면 해당 열이 총 몇 가지 관측치로 구성되어 있는지 한눈에 확인할 수 있다.
- distinct() 함수는 한번에 여러개의 열을 지정할 수도 있다.
ex) cyl 열과 gear 열에서 동시에 중복값 제거하기
distinct(mtcars, cyl, gear)
- 이때 cyl열과 gear열의 모든 값이 동일할 때만 제거된다.
4. 데이터 요약 및 샘플 추출하기
- 전체 데이터를 평균이나 중앙값, 최솟값 등으로 요약하거나, 전체 데이터에서 무작위로 데이터 샘플을 추출할 때 사용하는 함수들
1) 데이터 전체 요약하기 : summarize() 함수
summarise() 함수 = summarize() 함수 : 기술 통계 함수와 함께 사용하여 데이터 요약을 확인할 때 사용
summarize(데이터, 요약한 컬럼의 새로운 이름 = 기술통계 함수(데이터의 컬럼 명))
ex) 자동차 실린더 개수(cyl)의 평균, 최솟값, 최댓값 파악하기
- mtcars 데이터 세트에서 반환할 열 이름을 cyl_mean, cyl_min, cyl_max로 지정하고 cyl 열의 평균, 최솟값, 최댓값을 반환
summarize(mtcars, cyl_mean = mean(cyl), cyl_min = min(cyl), cyl_max = max(cyl))
- 위처럼 기술통계 함수로 반환할 열 이름을 지정해도 되지만, summarize(데이터, 기술통계함수(컬럼명)) 이렇게 또는 열 이름을 따로 지정하지 않아도 사용할 수 있다.
ex) mtcars에서 cyl열의 평균, 최솟값, 최댓값 반환하기 (새로운 이름 지정 x)
summarize(mtcars, mean(cyl), min(cyl), max(cyl))
- 이때는 열 이름을 따로 지정하지 않았으므로 실행한 기술통계 함수가 열 이름으로 출력된다.
2) 그룹별로 요약하기 : group_by() 함수
summarize() 함수 : 데이터 전체를 요약할 때 사용
group_by() 함수 : 그룹별로 데이터를 요약할 때 사용
group_by(데이터, 변수명)- group_by() 함수는 데이터를 지정한 조건에 따라 그룹으로 묶는 역할을 하므로 단독으로 쓰기보다는 다른 함수와 같이 사용하는 경우가 많음
ex) mtcars 데이터 세트에서 동일한 실린더 개수(cyl)를 가진 차가 몇대나 있는지 확인하기
gr_cyl <- group_by(mtcars, cyl)
summarize(gr_cy1, n())
n() 함수 : 데이터 개수를 구하는 기술통계함수
- 결과를 해석하면, cyl의 값의 종류는 3가지 (4, 6, 8)이며, 그 개수는 각각 11, 7, 14개임을 알 수 있다. (완전유용!)
- 만약 특정 열의 중복 값을 제외하고 개수를 파악하려면, n_distinct() 함수를 사용한다.
ex) cyl 열 그룹에서 gear 값이 중복인 데이터를 제외한 개수를 구하기
gr_cyl2 <- group_by(mtcars, cyl)
summarize(gr_cy12, n_distinct(gear))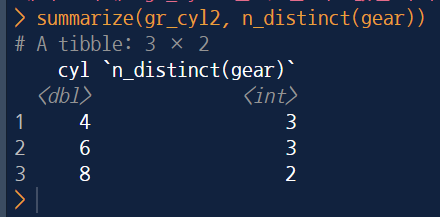
- gear값이 중복인 데이터를 제외하면, 4, 6, 8이라는 cyl값이 각각 3, 3, 2개 있음을 알수있다.
* 주의할점 : n() 함수와 n_distinct() 함수는 단독으로 사용할 수 없다. summarize(), mutate(), filter() 함수에서만 사용할 수 있다.
3) 샘플 추출하기 : sample_n(), sample_frac() 함수
- 데이터에서 임의로 샘플 데이터를 추출할 때는 sample_n() 함수와 sample_frac() 함수를 사용한다.
- sample_n() 함수 : 전체 데이터에서 샘플 데이터를 개수 기준으로 추출
sample_n(데이터, 샘플 추출할 개수)- sample_frac() 함수 : 전체 데이터에서 샘플 데이터를 비율 기준으로 추출
sample_frac(데이터, 샘플 추출할 비율)
ex) mtcars 데이터셋에서 샘플 데이터 10개 추출하기
sample_n(mtcars, 10)
- 샘플 데이터는 전체 데이터에서 데이터를 무작위로 추출하므로 동일한 코드라도 실행할 때마다 결과가 다르게 나온다.
ex) mtcars 데이터셋에서 전체 데이터의 30%를 샘플로 추출하기
sample_frac(mtcars, 0.3)
- 마찬가지로 코드 실행시 마다 결과가 다르게 나옴 (무작위 추출)
5. 파이프 연산자 : %>%
파이프 연산자 (pipe operator) : 이름 그대로 파이프, 연결하여 연산하는 연산자
데이터 세트 %>% 조건 또는 계산 %>% 데이터 세트%>% 연산자 : 함수를 연달아 사용할 때 함수 결괏값을 변수로 저장하는 과정을 거치지 않아도 됨.
값을 받아 바로 함수를 이어 사용할 수 있기 떔에 전체 코드가 간결해져 가독성이 좋아짐
- 파이프 연산자 %>% 단축키 : CTRL + SHIFT + M
ex)
gr_cyl <- group_by(mtcars, cyl)
summarize(gr_cy1, n())앞에서 했던거. 변수 새로만드는 과정 없이 파이프 연산자를 사용해서 한번에 코드 작성하기
group_by(mtcars, cyl) %>% summarize(n())
- 실행 결과는 같고 코드는 훨씬 간단하다. 이처럼 파이프 연산자는 %>% 기준으로 앞에 있는 함수의 결괏값을 먼저 구한 후 뒤에 있는 함수에 반영된다.
ex) mutate() 함수로 연비별(mpg) 순위를 추가한 후 순위를 기준으로 정렬하기
mp_rank <- mutate(mtcars, mpg_rank = rank(mpg))
arrange(mp_rank, mpg_rank)
- 같은 작업을 파이프 연산자를 사용하여 작성하기
mutate(mtcars, mpg_rank = rank(mpg)) %>% arrange(mpg_rank)
'기타 > R' 카테고리의 다른 글
| R 독학하기 - 5 (3. 데이터 구조 변형) (0) | 2024.02.22 |
|---|---|
| R 독학하기 - 5 (2. 데이터 가공) (1) | 2024.02.22 |
| R 독학하기 - 4 (3) (1) | 2024.02.15 |
| R 독학하기 - 4 (2) (1) | 2024.02.14 |
| R (R studio) 업데이트하는 방법 / 패키지 업데이트하는 방법 (1) | 2024.02.13 |



